Bio
I’m a final year PhD candidate at the University of Southern California. I am part of Intelligence and Knowledge Discovery Lab ( INK lab ), supervised by Prof. Xiang Ren. In the past, I was an intern at Microsoft Research, and Google.
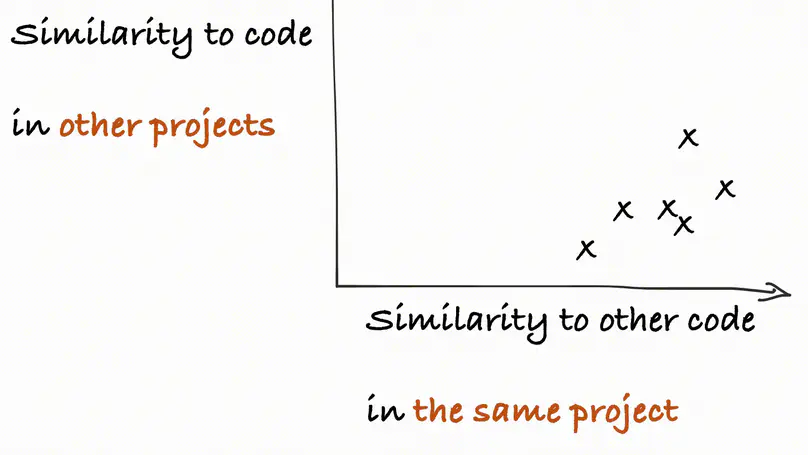
I am currently on the industry job market, my research experience is in large language models and their generalization, in particular in applications to software and code. I am open to jobs in many topics in NLP/LLMs, with specific interest in ensuring robustness, reliability, and safety of deployed NLP models.
- AI for Code
- Large Language Models and Generalization
- Machine Learning
PhD in Computer Science, 2017-present
University of Southern California
MPhil in Advanced Computer Science, 2016
University of Cambridge
BSc in Applied Mathematics and Informatics, 2014
Russian-Armenian (Slavonic) University
Featured Publications

Experience
Contact
- first name at isi dot edu
- DM Me